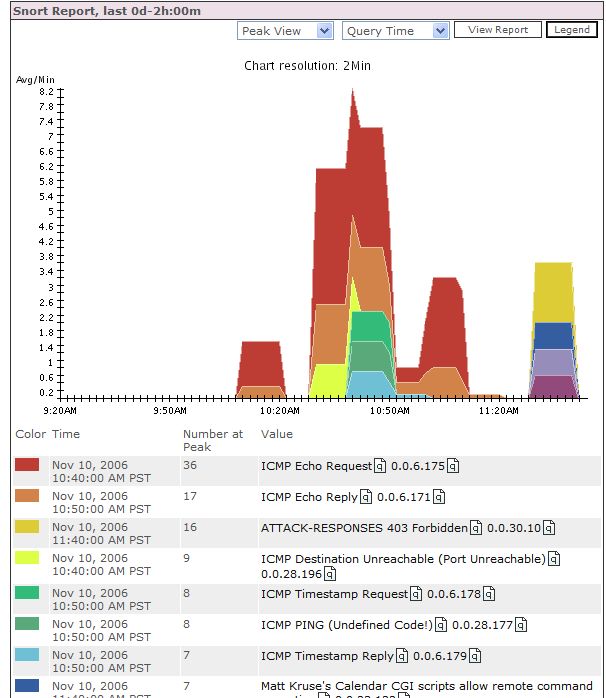
As promised the first of the Cisco MARS Blog Guest Articles.
I can guarantee the author below Matthew Hellman has either provided the answer or provided some input into the solution to virtually every question! Matthew works for a fortune 250 financial services company in the
In his Article, he explains more on the Archiving process in a busy network, and how you can create a 3rd Party Application to make use of the data that has been archived onto a NFS server.
The following information is based on my own personal experiences with CSMARS. Many assumptions have been made based on observed behavior that may be dependent on my particular environment. YMMV.
Key Benefits of Archiving
Even in the most modest of CSMARS deployments, a considerable amount of effort is required to initialize, tune and maintain the configuration of the appliance. The primary reason for enabling the archive functionality in CSMARS is so that it can be used to recover configuration data in the event of a disaster. This alone should provide enough incentive to deploy an archive server and enable the functionality. There is however a secondary and perhaps equally important reason for enabling the archive functionality; it is currently the only way to guarantee that raw events will be saved for a specific length of time.
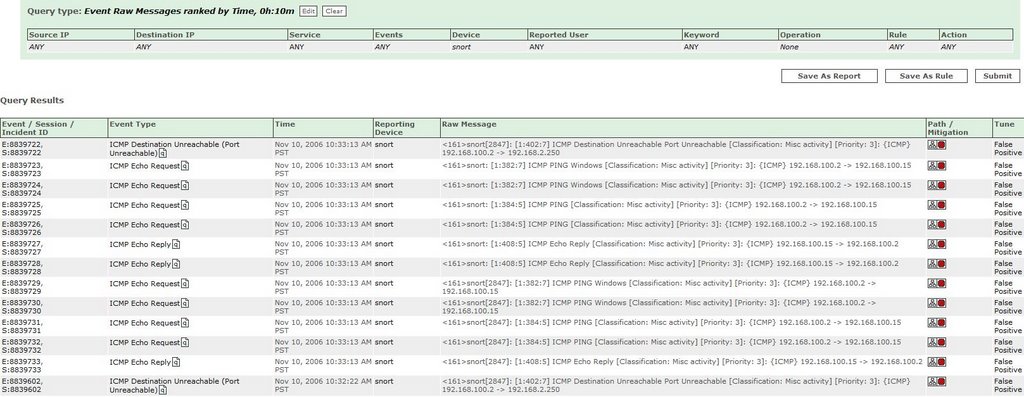
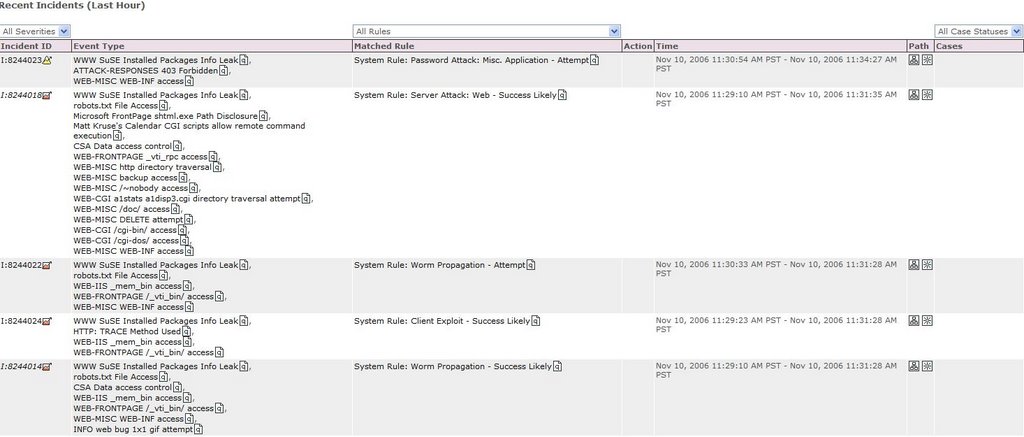
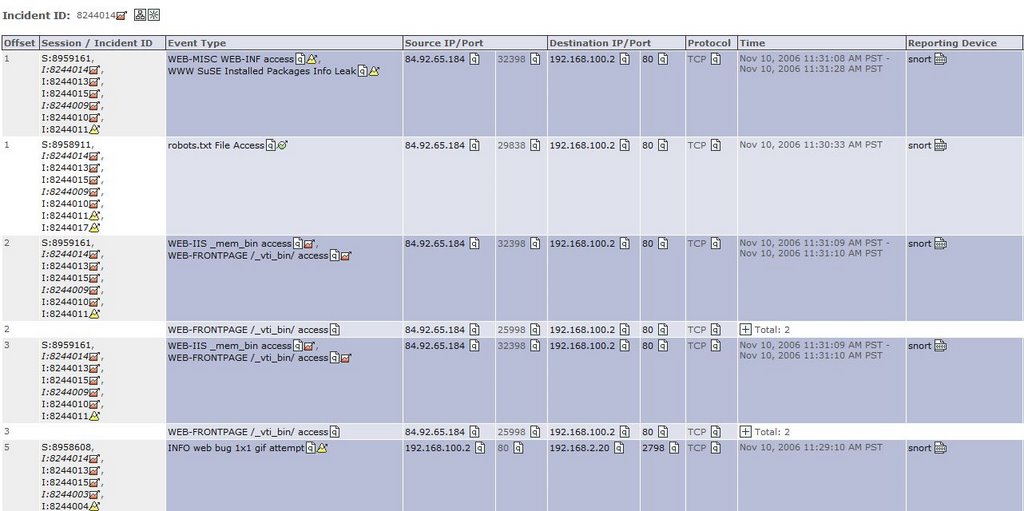
Many new users don’t initially realize that raw events, events, sessions, and particularly incidents in CSMARS don’t necessarily stick around very long. They are considered “dynamic” data and their lifespan is dependent on the MARS model and how busy the network is. When the database starts to fill up, the oldest dynamic data is purged. For example, dynamic data in one of our MARS 100e appliances, operating at near capacity, has a lifespan of less than 3 weeks. There are many variables that impact this lifespan, so as usual YMMV.
The only way to make dynamic data “permanent” is to assign it to a case (technically this copies the information, leaving the original dynamic data to be purged). However, this still does not save the raw events.
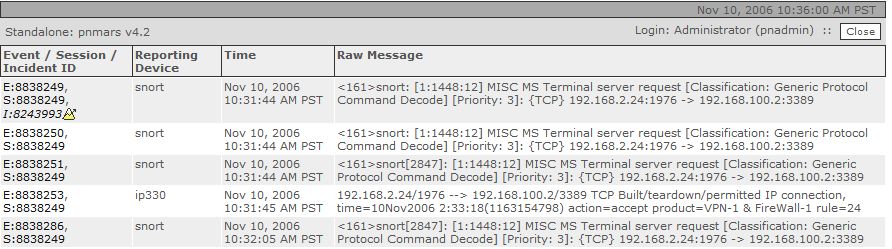
If you attempt to click the raw event link in a case [that is older than the lifespan of dynamic data], you will get the dreaded PSOD(pink screen of death):
Key Benefits of Archiving
Even in the most modest of CSMARS deployments, a considerable amount of effort is required to initialize, tune and maintain the configuration of the appliance. The primary reason for enabling the archive functionality in CSMARS is so that it can be used to recover configuration data in the event of a disaster. This alone should provide enough incentive to deploy an archive server and enable the functionality. There is however a secondary and perhaps equally important reason for enabling the archive functionality; it is currently the only way to guarantee that raw events will be saved for a specific length of time.
Many new users don’t initially realize that raw events, events, sessions, and particularly incidents in CSMARS don’t necessarily stick around very long. They are considered “dynamic” data and their lifespan is dependent on the MARS model and how busy the network is. When the database starts to fill up, the oldest dynamic data is purged. For example, dynamic data in one of our MARS 100e appliances, operating at near capacity, has a lifespan of less than 3 weeks. There are many variables that impact this lifespan, so as usual YMMV.
The only way to make dynamic data “permanent” is to assign it to a case (technically this copies the information, leaving the original dynamic data to be purged). However, this still does not save the raw events.
If you attempt to click the raw event link in a case [that is older than the lifespan of dynamic data], you will get the dreaded PSOD(pink screen of death):

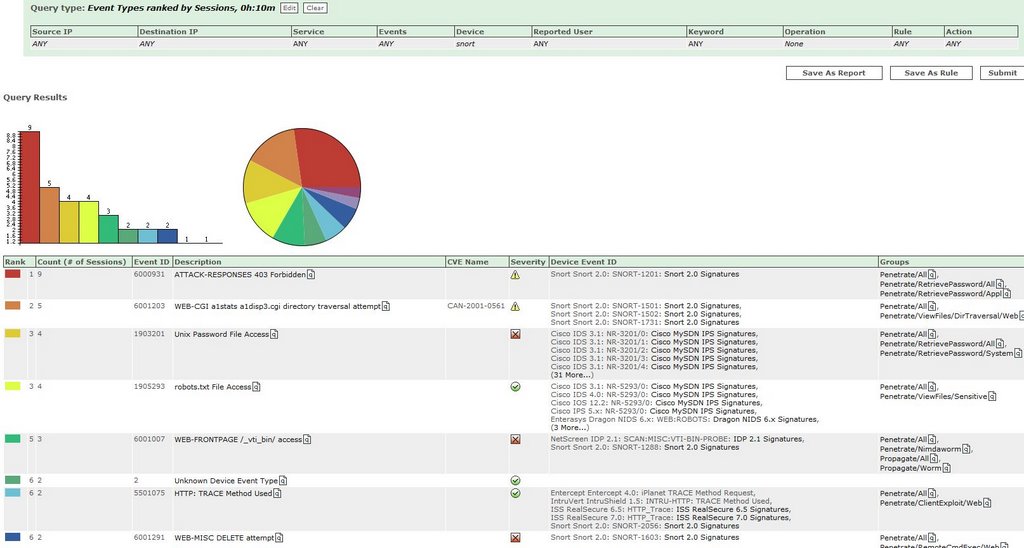
Quick & Dirty Raw Message Search
With archiving enabled, you will have all the data required to recover an appliance in the event of a disaster. In addition, raw messages will be archived for a known length of time. That’s great, but how does one go about querying the raw messages? Unfortunately, CSMARS doesn’t provide an interface for this purpose. There is an interface for retrieving raw events from the archive, but you can only enter a date and time range…you can’t really search. What if you want to see login messages for a particular user going back a whole year? Or maybe you want to see all the raw messages received from a particular reporting device for a 1 week period. You can’t do that using existing CSMARS functionality. Luckily though, this can be accomplished with as little as a single command on the archive server itself (provided you run Linux).
I have a UNIX background and we already have many RedHat servers, so it was natural to implement archiving on a RedHat box. Cisco also supports archiving to a Windows server running NFS. This decision drives the selection of the tools one might use to search the archive. The information and examples below were developed on a RedHat system, but most of the information and certainly the concepts are applicable to either.
In order to more intelligently search the archive, we must first understand the layout of the archive directories and format of the relevant files. Here is a diagram of the directory layout:

As you can see, each day has its own directory in the archive. There are multiple directories within each day directory. The only one we care about though is the ES directory (which one might assume stands for (E)vents and (S)essions). This is the directory that contains the raw events. There are only two types of files in the ES directory. The “rm-“ files are the raw message files, so they’re the files we want to work with. The “es-“ files are presumed to have something to do with normalized events and sessions and appear to contain a bunch of foreign key values…nothing really useful outside the database environment. Both types of files are compressed with the Ziv-Lempel algorithm, which means they can be uncompressed with just about any compression utility.
I have a UNIX background and we already have many RedHat servers, so it was natural to implement archiving on a RedHat box. Cisco also supports archiving to a Windows server running NFS. This decision drives the selection of the tools one might use to search the archive. The information and examples below were developed on a RedHat system, but most of the information and certainly the concepts are applicable to either.
In order to more intelligently search the archive, we must first understand the layout of the archive directories and format of the relevant files. Here is a diagram of the directory layout:

As you can see, each day has its own directory in the archive. There are multiple directories within each day directory. The only one we care about though is the ES directory (which one might assume stands for (E)vents and (S)essions). This is the directory that contains the raw events. There are only two types of files in the ES directory. The “rm-“ files are the raw message files, so they’re the files we want to work with. The “es-“ files are presumed to have something to do with normalized events and sessions and appear to contain a bunch of foreign key values…nothing really useful outside the database environment. Both types of files are compressed with the Ziv-Lempel algorithm, which means they can be uncompressed with just about any compression utility.
The format of the file names gives us important information about the data within:

At this point, we have all the details required to determine which files are relevant given a particular date and time range. Hopefully you can envision how you might build a regular expression to match on a range of days. For help with regular expressions, try this link.
Now, onto the format of the data within the files. Below is a copy of a single row from a file:

Now, onto the format of the data within the files. Below is a copy of a single row from a file:

Notice that the field delimiter is hex character xBB. Also remember that raw messages are currently truncated to 512 bytes. Don’t assume that rows within the file are sorted by date/time, because they aren’t (i.e. the first row will not always have the start date and start hour from filename).
Certainly one of the advantages to deploying the archive on Linux is that the basic tools necessary to search through compressed data are already available. For example, zgrep is a wrapper script found in most Linux distros that allows the user to perform regular expression searches through compressed data. Let’s say you want to find all instances where the Windows Administrator account was used in a security context on December 12-14, 2006 during the 1am hour.
The following command is all you need:
# zgrep –i –P “MSWinEventLog.*Security.*[ ]administrator[ ]” /archive/2006-12-1[234]/ES/rm*_2006-12-1[234]-01-??-??_*
That’s it! The zgrep command alone may satisfy basic search requirements. In an environment that processes many millions of events per day and/or keeps archived data for years however, something a little more sophisticated is needed.
Certainly one of the advantages to deploying the archive on Linux is that the basic tools necessary to search through compressed data are already available. For example, zgrep is a wrapper script found in most Linux distros that allows the user to perform regular expression searches through compressed data. Let’s say you want to find all instances where the Windows Administrator account was used in a security context on December 12-14, 2006 during the 1am hour.
The following command is all you need:
# zgrep –i –P “MSWinEventLog.*Security.*[ ]administrator[ ]” /archive/2006-12-1[234]/ES/rm*_2006-12-1[234]-01-??-??_*
That’s it! The zgrep command alone may satisfy basic search requirements. In an environment that processes many millions of events per day and/or keeps archived data for years however, something a little more sophisticated is needed.
Building a more sophisticated solution
As previously mentioned, we chose to use RedHat Linux as our NFS archive server. It’s a relatively beefy Intel box with dual 64-bit processors, 4GB ram, and >2TB storage.
Our CSMARS 100e processes in the neighborhood of 80 million events per day. This translates into as many as 400 raw message files written to the archive per day, and each file can contain over 70mb of uncompressed data. That’s a huge amount of data that must be searched though.
Our high level requirements for the solution were that it must be fast and it must be easy to use. We recognized early on that in order to search through this much data efficiently, we needed to spawn multiple processes. We also knew that running multiple searches concurrently was not feasible. To support these requirements, the following individual components were developed (in Perl, our language of choice):
Our CSMARS 100e processes in the neighborhood of 80 million events per day. This translates into as many as 400 raw message files written to the archive per day, and each file can contain over 70mb of uncompressed data. That’s a huge amount of data that must be searched though.
Our high level requirements for the solution were that it must be fast and it must be easy to use. We recognized early on that in order to search through this much data efficiently, we needed to spawn multiple processes. We also knew that running multiple searches concurrently was not feasible. To support these requirements, the following individual components were developed (in Perl, our language of choice):
- user facing CGI to create/read/update/delete search jobs
- a job manager that maintains the queue, starts search jobs, and notifies user of job status
- a query program that actually performs the search
- written in Perl
- allows PCRE searches
- includes recipes for common searches (checkpoint control transactions, windows login, etc)
- uses configuration files for most options
- supports any number of child search processes, as determined by configuration file
- limits maximum size of search results, as determined by configuration file
- auto detects when regular expression search is required
- performs case insensitive searches, as determined by configuration file
- compresses search results > n bytes, as determined by configuration file
- notifies user when job status changes
I spent only about 60 hours building a solution written in Perl, thanks in no small part to the judicious use of other peoples work via existing modules. Most of the harder stuff I had never done before (forking processes, managing a job queue), so I know this can be done by anyone with the ability to find and combine the right tools. This solution is the only method we have for viewing raw messages that have been purged from CSMARS, and it is serving that purpose exceedingly well. Not surprisingly, it has proven to be orders of magnitude faster at searching through events that have not yet been purged from CSMARS. A keyword query for a specific username during the last 2 weeks takes over 11 hours when done in our CSMARS. The same search takes 13 minutes using the custom search tool. This has led to the solution becoming an extremely useful tool for troubleshooting general operational issues with reporting devices.
My work does not permit me to share the code developed as part of my job, so I can’t provide it. I’m a terrible hack anyway, so you wouldn’t want it;-) My basic pseudo-code is simple enough though:
My work does not permit me to share the code developed as part of my job, so I can’t provide it. I’m a terrible hack anyway, so you wouldn’t want it;-) My basic pseudo-code is simple enough though:
- create a list of files that must be searched based on provided time range
- for each file, spawn a child process to perform the search, writing results to unique file based on pid
- wait for all children to exit, then clean up the output

I will share a snippet of the code that encompasses the main logic of the search program. This is just an example of how one might fork processes in Perl.
foreach my $file ( @dayfilelist ) {
## for each file that must be searched through, we fork a child process. Limited using Proc::Queue (see $maxkids)
if ($pid = fork) {
# parent process
push(@pids,$pid);
}
elsif (defined $pid) {
# child process
# if we've already written > max results size, we're done
my ($dirsize) = split(/\t/,`du -sb "$jobdir/$jobid"`);
exit(0) if $dirsize > $maxresultsize;
print STDERR "Kid: started processing ".substr($file,-56)." at ".scalar localtime()."\n" if $statusfl;
# perform our search on this file
my $results = `$zgrep $caseopt $pcreopt "$searchStr" $file`;
exit(0) unless $results; #if we don't have any results, exit
# create individual output files for each child
open (OFILE,">$ofile.$$") or die "Unable to open $ofile.$$ for writing: $!";
print OFILE $results or die "Can't write to output file: $!";
close OFILE or die "Can't close output file: $!";
print STDERR "Kid: done processing ".substr($file,-56)." at ".scalar localtime()."\n" if $statusfl;
exit(0);
} ## end child process
else {
# forkin' error
die "Can't fork: $!\n";
}
} # end of loop through files
# wait for all children to finish
Proc::Queue::waitpids(@pids);
Matthew Hellman
I`d like to thank Matthew, for sharing his knowledge and experience of creating a 3rd Party Application with us, and I must admit i didn`t even think this was possible! Thanks again Matthew.